多任务
Preemptive Multitasking 抢占式多任务
核心思想是操作系统控制什么时候切换任务。
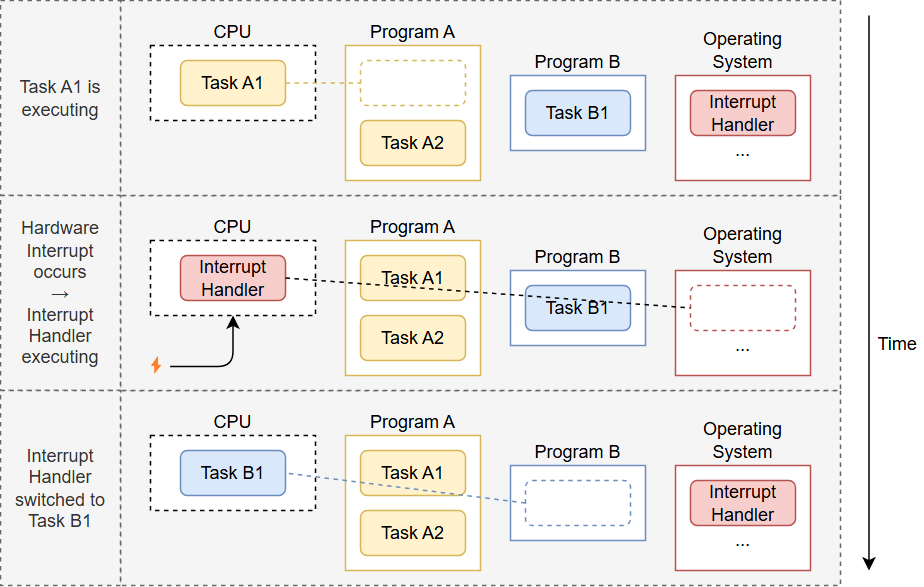
第一行中,CPU 正在执行程序 A 的任务 A1。在第二行中,CPU 收到一个硬件中断。如硬件中断一文所述,
CPU 会立即停止执行任务 A1,并跳转到中断描述符表 (IDT) 中定义的中断处理程序。通过该中断处理程序,
操作系统现在可以再次控制 CPU,从而切换到任务 B1,而不是继续执行任务 A1。
保存状态
由于任务会在任意时间点被中断,它们可能正在进行某些计算。为了能在稍后恢复任务,操作系统必须备份任务的整个状态,
包括其调用堆栈(call stack)和所有 CPU 寄存器(cpu register)的值。这个过程称为上下文切换(context switch)。
由于调用堆栈可能非常庞大,操作系统通常会为每个任务建立单独的调用堆栈,而不是在每个任务切换时备份调用堆栈内容。
这种拥有自己堆栈的任务称为执行线程(thread of execution),简称线程(thread)。
通过为每个任务使用单独的堆栈,在上下文切换时只需保存寄存器内容(包括程序计数器和堆栈指针)。
这种方法最大限度地减少了上下文切换的性能开销,这一点非常重要,因为上下文切换通常每秒会发生 100 次。
优缺点
优点:
1. 操作系统保证 cpu 分配时间公平
缺点:
1. 每个程序需要保存单独的 stack,浪费内存
2. 操作系统需要为每次切换保存 cpu register 状态,即使任务只用了很少一部分 register
Cooperative Multitasking 协作式多任务
核心思想是程序可以主动交出 cpu 控制权。
保存状态
由于任务自己定义暂停点,因此它们不需要操作系统来保存状态。
相反,它们可以在自己暂停之前准确保存继续运行所需的状态,这通常会带来更好的性能。
例如,Rust 的 async/await 实现会将所有仍需使用的局部变量存储在自动生成的结构体中(见下文)。
通过在暂停前备份调用栈的相关部分,所有任务都可以共享一个调用栈,从而大大降低了每个任务的内存消耗。这样就可以创建几乎任意数量的任务,而不会耗尽内存。
优缺点
优点:
1. 性能高
缺点:
1. 一些任务可能占有全部资源,其它任务获取不到 cpu 时间
rust 中的 async/await
Future
Future 代表一个现在还不能用的值。
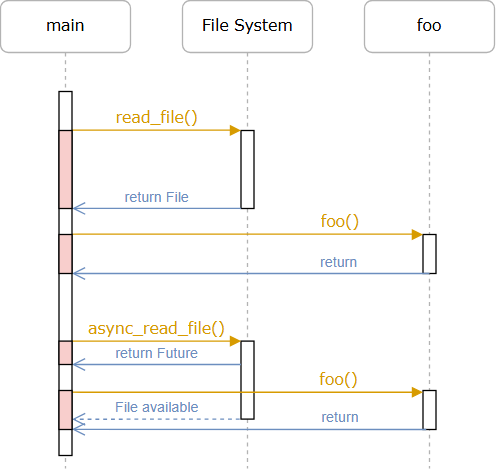
Future 读取
// 一种方法,浪费cpu资源
let future = async_read_file("foo.txt");
let file_content = loop {
match future.poll(…) {
Poll::Ready(value) => break value,
Poll::Pending => {}, // do nothing
}
}
// 另一种方法,代码难以维护
fn example(min_len: usize) -> impl Future<Output = String> {
async_read_file("foo.txt").then(move |content| {
if content.len() < min_len {
Either::Left(async_read_file("bar.txt").map(|s| content + &s))
} else {
Either::Right(future::ready(content))
}
})
}
async/await
async/await 核心思想是可以同步代码,由编译器来转换为异步代码。
以下代码仍然是异步代码:
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
状态机
编译器把 example 函数变成了一个状态机,每个 await 都是一个状态。状态机实现 Future,每次 poll 的时候根据状态不同,走不同的逻辑:
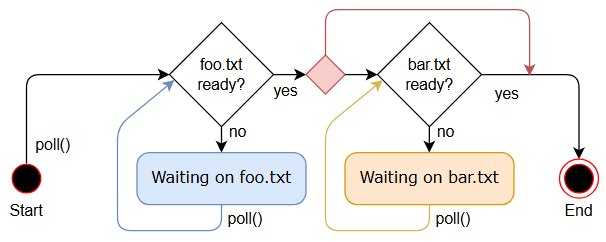
状态保存
由于是状态机,因此需要保存状态,编译器此时就可以派上用场了,它知道哪些变量有用到,哪些没有。因此它可以生成一些临时的 struct,如下:
// example 函数
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
// 编译器生成的状态 struct:
struct StartState {
min_len: usize,
}
struct WaitingOnFooTxtState {
min_len: usize,
foo_txt_future: impl Future<Output = String>,
}
struct WaitingOnBarTxtState {
content: String,
bar_txt_future: impl Future<Output = String>,
}
struct EndState {}
Future 与 Pin
通过 async/await 创建的 future 实例通常是自引用的。用 Pin 将 Self 包裹起来,并让编译器生成状态机的各种 struct 时,
略过实现 Unpin,这样就保证了 future 实例不会在 poll 的时候被 move 走,也就是保证了所有的自引用都不会变成悬空引用。
绝大多数类型都不在意是否被移动,也就是自动实现了 UnPin 特征。
而被结构体 Pin 包裹的值,会实现 !UnPin 特征,也就是没有实现 UnPin。
通过下方式可以实现 !UnPin,而一旦一个字段实现了 !UnPin,整个结构体就实现了 !UnPin.
use std::marker::PhantomPinned;
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
_marker: PhantomPinned, // 这是一个标记
}
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>